一次apache Segmentation fault (11) 崩溃问题定位
这些天出了一个很严重的问题。php接口,或者某个页面,会突然访问不了,查看apache错误日志,发现是不断的apache Segmentation fault (11),访问就会出现崩溃,之后所有的请求都会失败了。
之后运维重启apache解决,但是之后惨无人道的崩溃大幕开始了,每天晚上十点多的时候,某个站就会跑出来崩溃下。在分析最近更新内容后,发现没有明显能导致崩溃的更新或者写法。于是开发不行运维补,伟大的运维大神在连续几天晚上两三点被叫起来尿尿的情况下,终于想到了一个好办法,监控apache error日志的Segmentation fault (11) ,出现就重启,粗糙猛的办法临时解决了问题。
但是原因还是要找的,万一啥时候监控不准或者忘了加,或者掉了,那就出大事了。在这种找不到具体问题,也没法知道是更新了什么的情况下,只有分析apache的崩溃文件了。于是叫运维大神开启了apache崩溃产生core文件的配置。抓到了一堆core文件,gdb强势插入,bt观察,core文件大致分2种,
第一种崩在

remove_header,而且参数是 content-type ,大概估计是移除这个content-type的时候,崩溃了,看了下php代码,没有手动设置删除content-type,设置content-type倒很多,但都不是新增的,还是无法直接定位到具体的原因。
第二种是:
在销毁op_array的地方,完整堆栈:
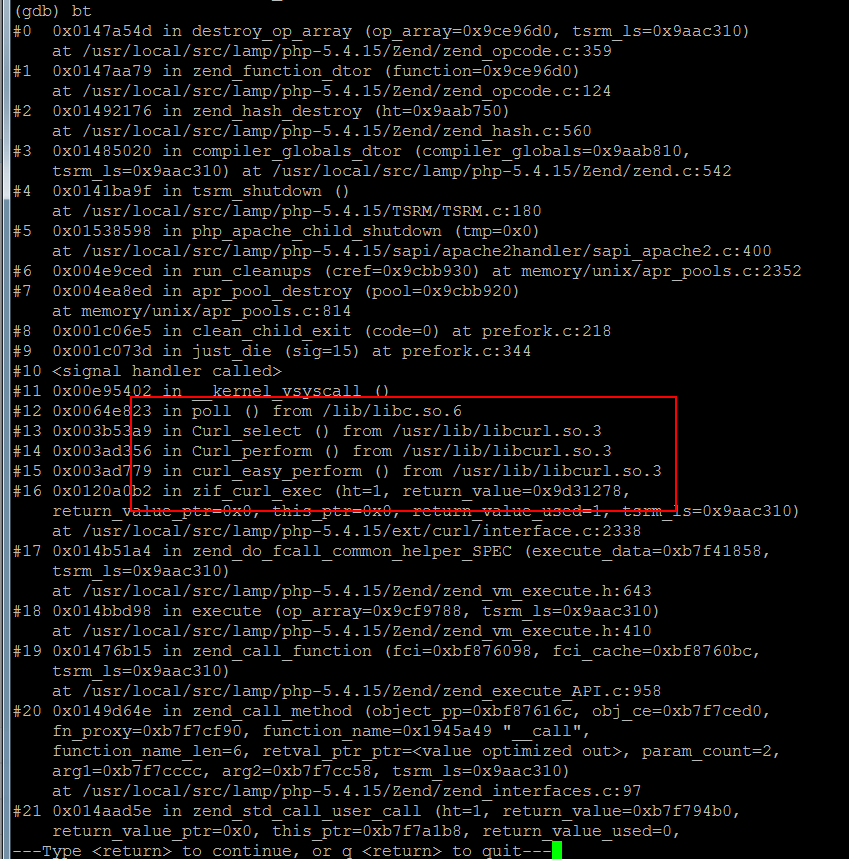
注意下12-16层,是curl的调用,curl出了很多bug,于是猜测是新增了什么大量调用curl的功能,但是检查发现没有。
继续看类似几个core文件,发现除了curl,其他core文件还有mysql,file_get_contents等函数出现,然后就崩溃了,难道是阿里云网络最近不稳定,导致涉及网络调用的代码崩溃了?再仔细看看调用:
#7 0x004ea8ed in apr_pool_destroy (pool=0x9cbb920)
at memory/unix/apr_pools.c:814
#8 0x001c06e5 in clean_child_exit (code=0) at prefork.c:218
#9 0x001c073d in just_die (sig=15) at prefork.c:344
#10
just_die (sig=15)应该是收到信号,然后apache退出,在释放资源的时候崩溃了,结合core文件生成的时候,能确定这种是产生Segmentation fault (11)后,监控脚本重启apache,然后apache进程在退出的时候,因为有网络调用的内容在跑,没处理好导致了崩溃,这种崩溃只在重启的时候才会发生,于是略过不管,真正致命的应该是第一种。
继续分析第一种core,完整堆栈信息
(gdb) bt
#0 sapi_remove_header (l=0x85e20e8, name=0xb7fc21a0 "Content-Type", len=12) at /usr/local/src/lamp/php-5.4.15/main/SAPI.c:601
#1 0x01426236 in sapi_header_add_op (op=, sapi_header=0xbff94460, tsrm_ls=0x85e2f60)
at /usr/local/src/lamp/php-5.4.15/main/SAPI.c:650
#2 0x01426e8b in sapi_header_op (op=SAPI_HEADER_REPLACE, arg=0xbff944a0, tsrm_ls=0x85e2f60)
at /usr/local/src/lamp/php-5.4.15/main/SAPI.c:842
#3 0x013b9415 in zif_header (ht=1, return_value=0xb7fc213c, return_value_ptr=0x0, this_ptr=0x0, return_value_used=0, tsrm_ls=0x85e2f60)
at /usr/local/src/lamp/php-5.4.15/ext/standard/head.c:48
#4 0x014b21a4 in zend_do_fcall_common_helper_SPEC (execute_data=0xb7fb210c, tsrm_ls=0x85e2f60)
at /usr/local/src/lamp/php-5.4.15/Zend/zend_vm_execute.h:643
#5 0x014b8d98 in execute (op_array=0xb7fb2070, tsrm_ls=0x85e2f60) at /usr/local/src/lamp/php-5.4.15/Zend/zend_vm_execute.h:410
#6 0x01480c7c in zend_execute_scripts (type=2, tsrm_ls=0x85e2f60, retval=0x0, file_count=1)
at /usr/local/src/lamp/php-5.4.15/Zend/zend.c:1315
#7 0x015364fb in php_handler (r=0x8801058) at /usr/local/src/lamp/php-5.4.15/sapi/apache2handler/sapi_apache2.c:669
#8 0x0808541b in ap_run_handler (r=0x8801058) at config.c:168
#9 0x08088fbb in ap_invoke_handler (r=0x8801058) at config.c:432
#10 0x0809a707 in ap_process_async_request (r=0x8801058) at http_request.c:317
#11 0x0809a83d in ap_process_request (r=0x8801058) at http_request.c:363
#12 0x08097230 in ap_process_http_sync_connection (c=0x87f4b20) at http_core.c:190
#13 ap_process_http_connection (c=0x87f4b20) at http_core.c:231
#14 0x0808f32b in ap_run_process_connection (c=0x87f4b20) at connection.c:41
#15 0x00fb6c59 in child_main (child_num_arg=) at prefork.c:704
#16 0x00fb6ffd in make_child (s=0x8570d48, slot=15) at prefork.c:800
#17 0x00fb7b13 in prefork_run (_pconf=0x854c0a8, plog=0x85729a0, s=0x8570d48) at prefork.c:902
#18 0x0806ddc9 in ap_run_mpm (pconf=0x854c0a8, plog=0x85729a0, s=0x8570d48) at mpm_common.c:96
#19 0x0806886a in main (argc=139763872, argv=0x87f2940) at main.c:777
调用层比较少,说明还没跑什么就崩溃了。
这里有两个地方能看到php信息,第5层的 execute 以及第4层zend_do_fcall_common_helper_SPEC 。看下op_array中的信息:
找到了崩溃的php文件main.php,但是这是一个入口文件。基本所有功能都走这进入,要定位的范围还是很大。
继续看下zend_do_fcall_common_helper_SPEC,在gdb中,可以手动打印出函数的变量,可以查看下源码,看传递进去的变量是什么结构,然后构造个指针查看。
不过php调试有简单方法。php有个gdb调试脚本,可以较快的将php执行信息输出来,不用盯着c的结构体看细节内容,
来执行一下:source /usr/local/src/lamp/php-5.4.15/.gdbinit
然后切到zend_do_fcall_common_helper_SPEC的上下文中,命令是frame 层数 缩写是f,执行f 4
dump_bt类似bt,是php的gdb调试脚本提供的方法,能看到当前执行环境的调用层次,我们这就看到一层,在header设置content-type的时候就崩掉了。
main.php源代码如下:
date_default_timezone_set('Asia/Shanghai');
header('Content-Type: text/html;charset=utf-8');
define('APP_PATH',dirname(__FILE__)."/aae");//tita base dir
define('ROOT_PATH',dirname(__FILE__));
require APP_PATH . '/core/Core.php';//加载框架核心
$app=\core\Tita::App();
$app->run();
根据dump_bt提示,崩在16行设置header的地方,也就是这里的第二行,这比较头痛,刚到入口apache就崩了,应该不是php语句写错了导致的。这样子也不好绕过,继续往上看:
#0 sapi_remove_header (l=0x85e20e8, name=0xb7fc21a0 "Content-Type", len=12) at /usr/local/src/lamp/php-5.4.15/main/SAPI.c:601
#1 0x01426236 in sapi_header_add_op (op=, sapi_header=0xbff94460, tsrm_ls=0x85e2f60)
at /usr/local/src/lamp/php-5.4.15/main/SAPI.c:650
#2 0x01426e8b in sapi_header_op (op=SAPI_HEADER_REPLACE, arg=0xbff944a0, tsrm_ls=0x85e2f60)
at /usr/local/src/lamp/php-5.4.15/main/SAPI.c:842
最终是崩在remove_header,我们是设置header,为什么会remove header呢, 看源码。
sapi.c 601 行
/*
* since zend_llist_del_element only remove one matched item once,
* we should remove them by ourself
*/
static void sapi_remove_header(zend_llist *l, char *name, uint len) {
sapi_header_struct *header;
zend_llist_element *next;
zend_llist_element *current=l->head;
while (current) {
header = (sapi_header_struct *)(current->data);
next = current->next;
if (header->header_len > len && header->header[len] == ':'
&& !strncasecmp(header->header, name, len)) {
if (current->prev) {
current->prev->next = next;
} else {
l->head = next;
}
if (next) {
next->prev = current->prev;
} else {
l->tail = current->prev;
}
sapi_free_header(header);
efree(current);
--l->count;
}
current = next;
}
}
这里对current这个结构体进行操作,l->head是个链表,在next = current->next;崩溃,当时的current是个已经损坏的zend_llist_element结构,导致继续遍历下个节点的时候崩溃了。注意这句:
zend_llist_element *current=l->head;
current最初是从l来的,幸好l还没损坏,
检查下链表指向
查看到第二个节点的时候,就发现异常了0x1d明显不像是个指针,也就是应该只有一个节点,第一个节点的next本来应该为null,这里却是一个不知道啥的值。在->next的时候就崩溃了
至此,大致情况清楚了:
我们的php程序在调用header('Content-Type: text/html;charset=utf-8');的时候,apache进入了sapi_remove_header,然后这个函数里,遍历header列表的时候,使用了一个未初始化或者已经释放或者不知道怎么被损坏的一个header链表。如何解决这个问题呢?既然我们不需要remove_header,那是不是不进入这里就可以了,再看下#1层的函数sapi_header_add_op,这应该是我们要操作的内容,设置header content-type
static void sapi_header_add_op(sapi_header_op_enum op, sapi_header_struct *sapi_header TSRMLS_DC)
{
if (!sapi_module.header_handler ||
(SAPI_HEADER_ADD & sapi_module.header_handler(sapi_header, op, &SG(sapi_headers) TSRMLS_CC))) {
if (op == SAPI_HEADER_REPLACE) {
char *colon_offset = strchr(sapi_header->header, ':');
if (colon_offset) {
char sav = *colon_offset;
*colon_offset = 0;
sapi_remove_header(&SG(sapi_headers).headers, sapi_header->header, strlen(sapi_header->header));
*colon_offset = sav;
}
}
zend_llist_add_element(&SG(sapi_headers).headers, (void *) sapi_header);
} else {
sapi_free_header(sapi_header);
}
}
源代码显示op == SAPI_HEADER_REPLACE时才会进入sapi_remove_header,也就是我们传进来就是replace,看手册:
void header ( string $string [, bool $replace = true [, int $http_response_code ]] )
原来默认设置成replace,这个参数的意思是当有同名header的时候替换较旧设置的那个header,我们这因为是入口,代码保证了这个header是第一个,所以,直接设置成false,来避免进入崩溃的函数sapi_remove_header。改成:header('Content-Type: text/html;charset=utf-8',false);
虽然崩溃问题解决了,但是为啥链表会是个坏的,因为崩溃几率小,压测设置header也不崩溃,所以还无法复现。