从网络包分析性能瓶颈点
date: 2022-04-17 16:48:22
在做系统性能分析的时候,压测tps上不去,怎么识别是压测机性能问题,还是接入层性能问题,还是应用性能问题,还是数据库性能问题?
无法用应用日志分析清楚的情况下,往往就需要网络层的抓包来分析堵点情况了。
拿一个经常遇到的典型场景分析, 用户->nginx->tomcat->外部服务
如图:

当性能出现瓶颈的时候,如何知道是哪里出问题了呢,一般情况下,先在backend service 服务器上抓包。
前置网络知识
tcp抓包大家应该不陌生,linux服务器上一般使用tcpdump工具,分析包有wireshake,有2个技巧,对分析海量抓包数据很有帮助。
1.快速分析网络包异常,wireshake->analyze->expert information:
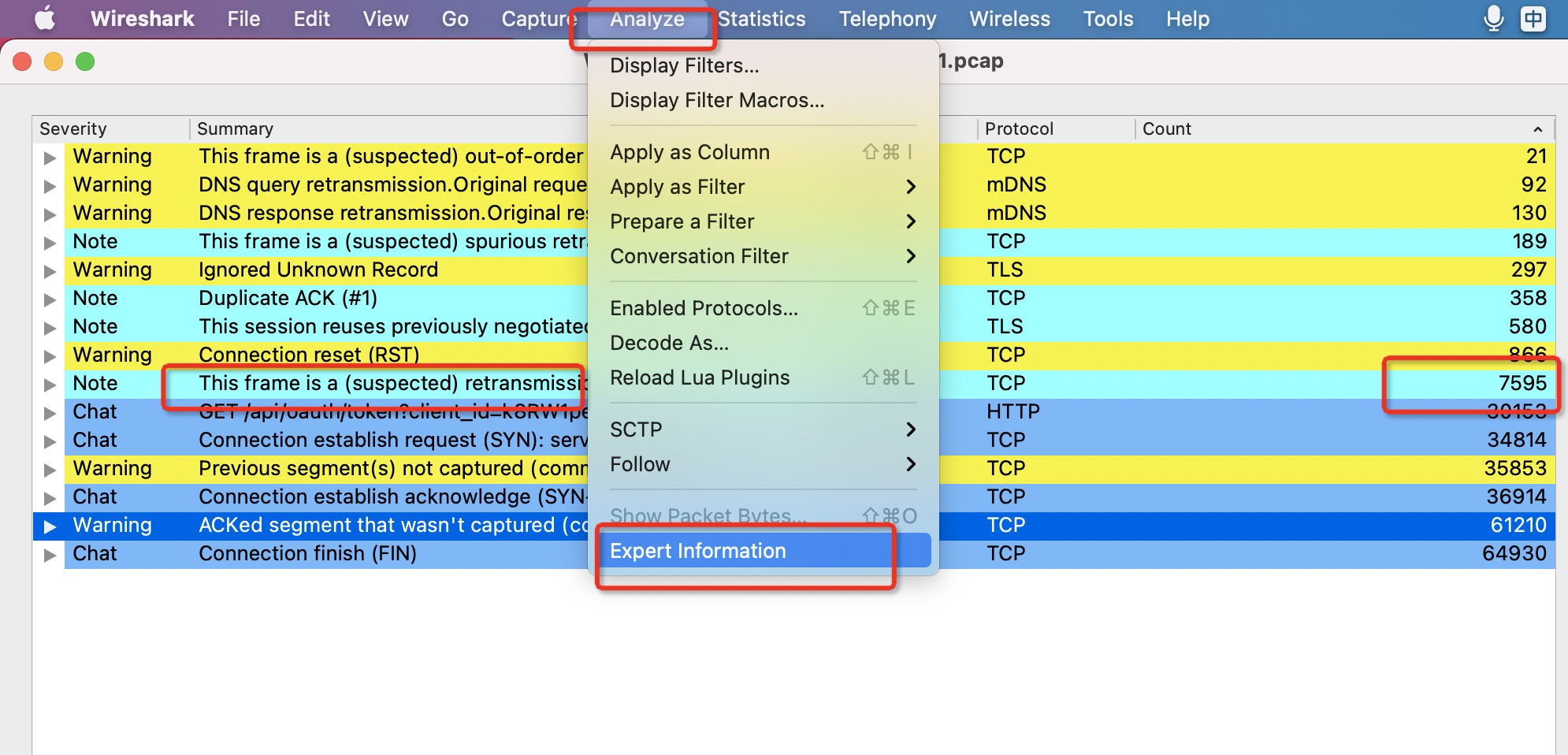
上述包就存在非常严重的重传,达到7k+次。
2.怎么快速找到传输时间较长的包,通常情况下达到性能瓶颈在网络层的表现要么是有rst,重传等错误报,还有就是包的返回时间非常慢,用下面方法可以快速找到哪些数据包传输慢:

第一种情况,后端服务器本身性能瓶颈
这种情况下,在后端服务器抓包,现象是: server -> 往前端服务发包慢

上图情况是tomcat 新建连接达到瓶颈(syn ack是tcp握手的第二步,分析前端往后端服务采用了短连接),改成长连接之后问题解决。
第二种情况,前端->后端服务链路有瓶颈
通常限速,或限连接数的情况下,会看到大量重传(参考上面第一种查看方法)
还是syn ack, 大量重传:
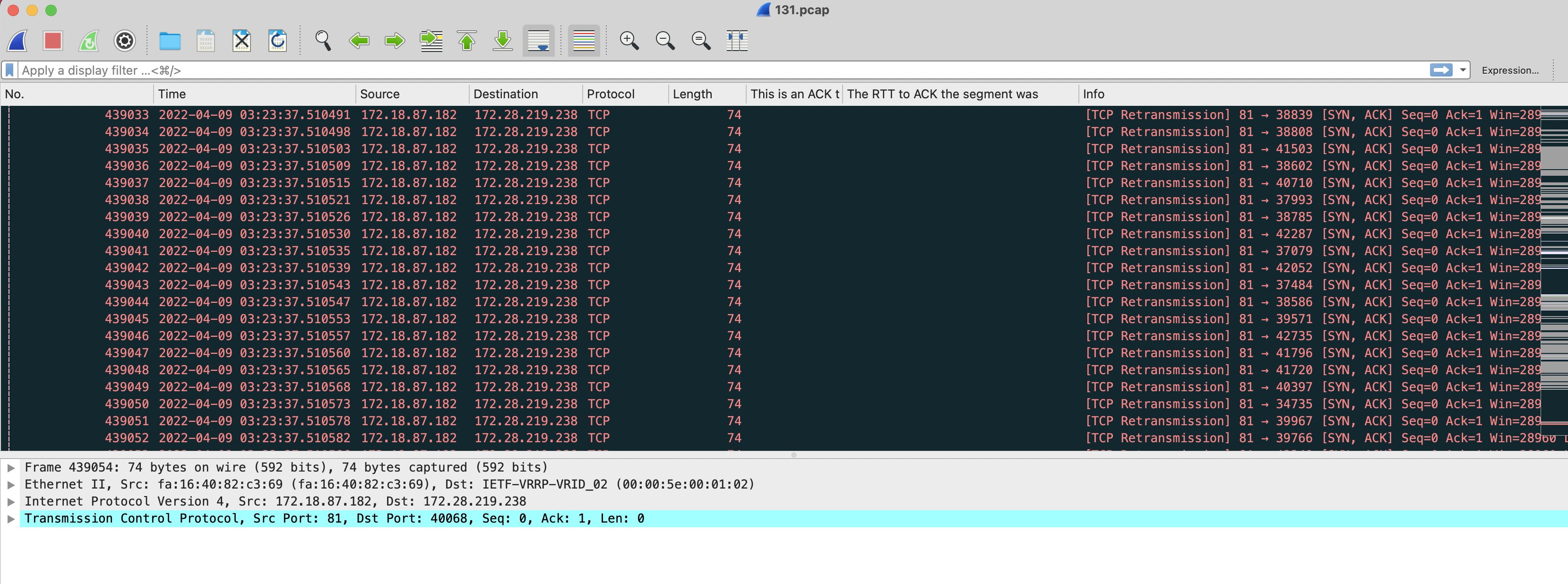
81->前端服务器的 syn ack回包都被丢了,tcp连接建不起来,原因在前端服务器没有收到ack的包,可能是前端服务器,或者中间链路有问题
第三种情况,后端->数据库等外部服务有瓶颈
这种情况,类似第一种情况,但是方向是反过来的,会在后端服务器上看到:
- 后端服务器->数据库服务器 SYN发包后:
- 数据库服务器回syn ack慢
- 或者后端服务器不断在发重传报过去(数据库服务器没回应)
总结
熟悉tcp握手原理,根据wireshake rtt, 重传等分析工具,可以快速定位到全链路上的异常节点。